import pandas as pd from sklearn.calibration import calibration_curve, CalibratedClassifierCV from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB
# load the data into a dataframe rain = pd.read_csv('seattleWeather_1948-2017.csv').dropna() rain.head()
# use the temperatures to predict whether or not there was rain that day features = rain[['TMIN', 'TMAX']] target = rain.RAIN.astype(bool) X_train, X_test, y_train, y_test = train_test_split(features, target, random_state=42)
# use a Naive Bayes Classifier and make hard predictions nb_rain = GaussianNB().fit(X_train, y_train) accuracy = nb_rain.score(X_train, y_train) print(f'The hard predictions were right {100*accuracy:5.2f}% of the time')
# use the predict_proba method to get the probability of the positive case predictions = nb_rain.predict_proba(X_train)[:, 1]
# call calibration_curve to "bin" similar predicted probabilities together, and calculate what percentage of the time # it actually rains in that bin binned_true_p, binned_predict_p = calibration_curve(y_train, predictions, n_bins=10)
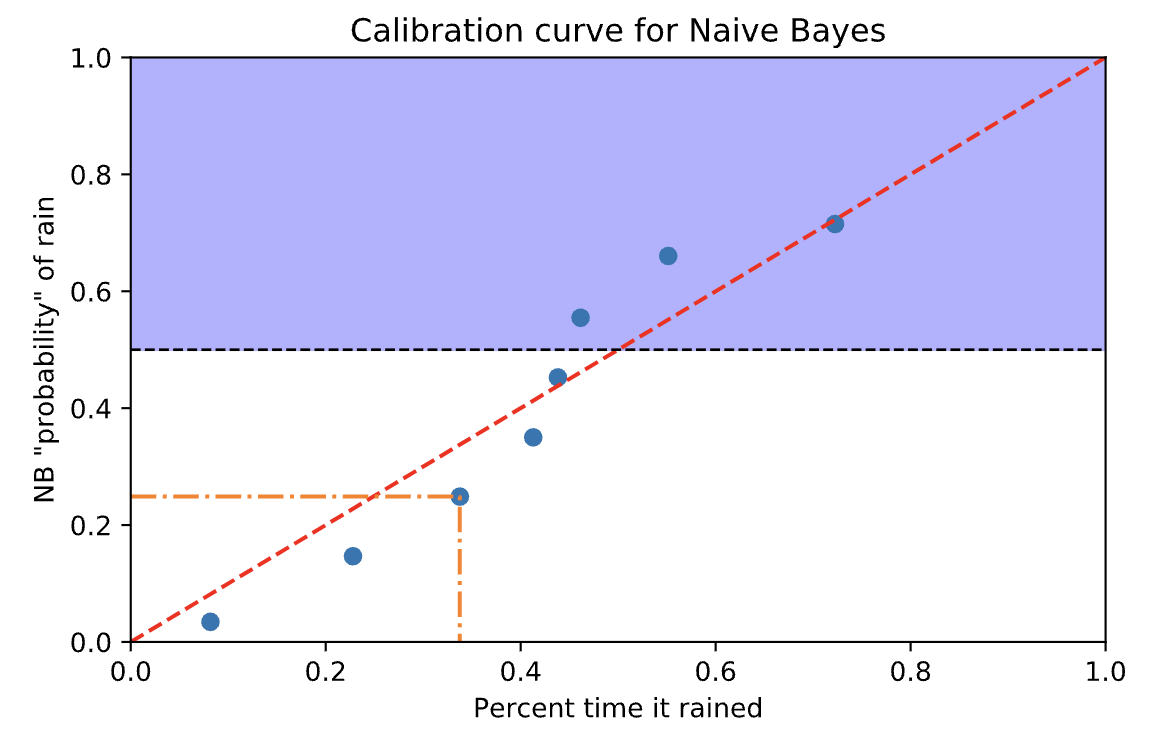
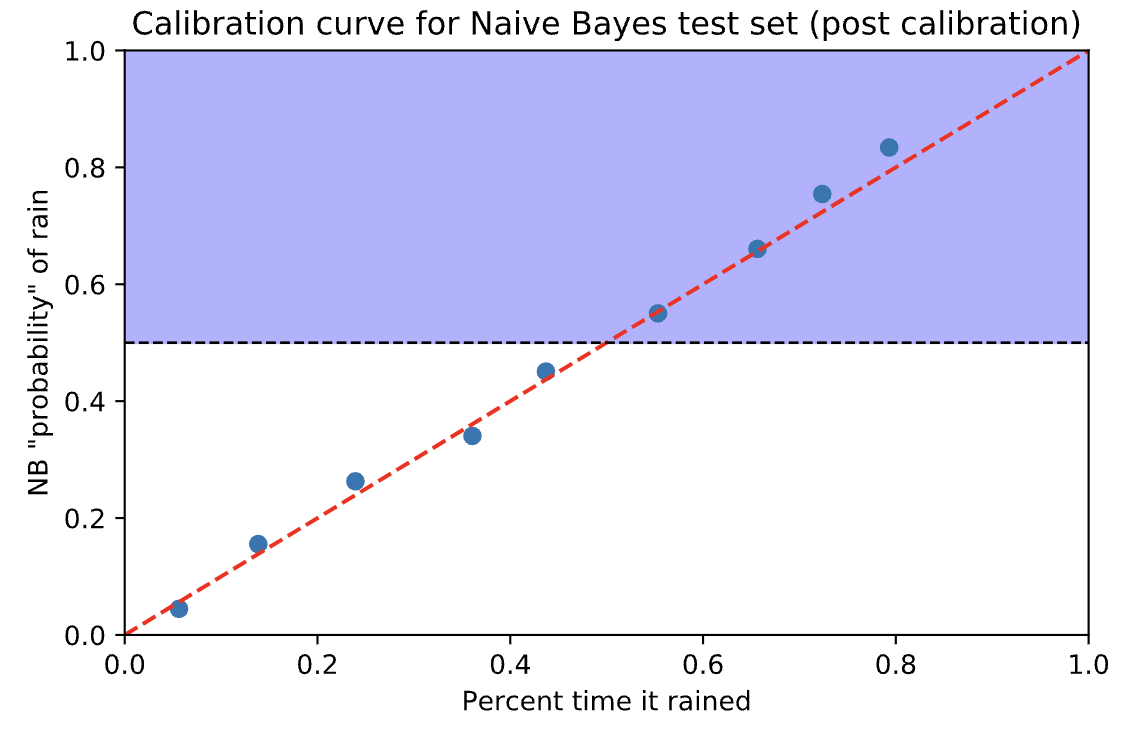 修正后的概率更接近红线。
修正后的概率更接近红线。