Proximal Policy Optimization (PPO)
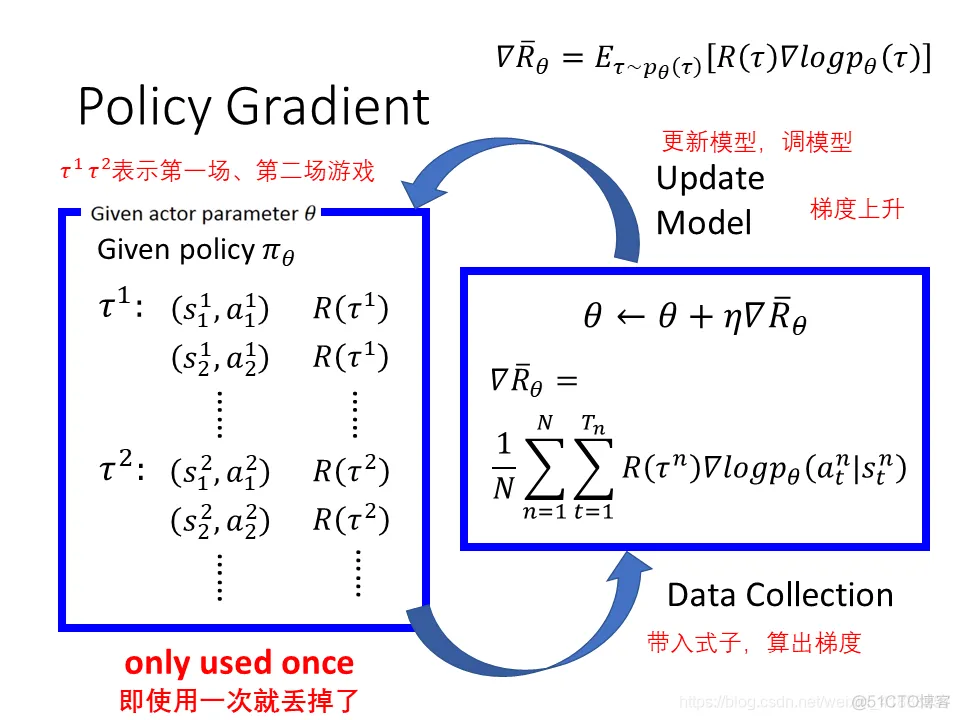
Policy Gradient
τ={s1,a1,s2,a2,⋯,sT,aT}
当参数是θ的时候某一个 trajectory 回合里面发生τ的几率:
pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)⋯=p(s1)t=1∏Tpθ(at∣st)p(st+1∣st,at)
Expect Reward,穷举所有的Trajectory不同回合的Reward乘以不同回合的几率再求和就是期望Reward
Rˉθ=τ∑R(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]
要求期望Reward最大值采用梯度上升
∇Rˉθ=τ∑R(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)∇logpθ(τ)=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈N1n=1∑NR(τn)∇logpθ(τn)
由于env的那部分p(st+1∣st,at)和无关θ,所以无需对其做 gradient,只需要对actor的那部分pθ(at∣st)做gradient,所以:
∇Rˉθ=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)
这里为什么要用一个log呢?(也就是为什么要多一个再除以p的操作)直接对p取梯度不好吗?因为如果动作a很好但是很罕见,而动作b很多但是不太好,但是在求和操作的时候,就会把b的Reward求和变得很大,为了使得目标函数最大,模型就会偏好出现几率较高action b,而这不是我们想要的。除以p的操作就是一个标准化的操作,出现次数越多也就是概率越大,除以自己就标准化了
On-policy -> Off-policy
前面的policy gradient的做法就是on-policy,即要learn的policy和与环境互动的policy是同一个。当update参数以后,从θ变成θ′,那么之前sample出来的data就不能用了。Update一次参数,只能做一次gradient acent,而后再去 collect data,非常耗时,所以需要 off policy。off-policy可以拿一批data用好几次。
Importance Sampling
从分布p中采样x,当p无法积分,那就约等于右边的均值
Ex∼p[f(x)]≈Ni=1∑Nf(xi)
假设:无法从p中采样data,只能从q中采样data,那么这个等式无法近似
Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)[q(x)p(x)]
变成从q 分布中采样data,q(x)p(x)相当于修正权重
Issue of Importance Sampling
期望相同,但是方差不同
VAR[X]=E[X2]−(E[X])2
f(x)的方差
Varx∼p[f(x)]=Ex∼p[f(x)2]−(Ex∼p[f(x)])2
f(x)q(x)p(x)的方差
Varx∼q[f(x)q(x)p(x)]=Ex∼q[(f(x)q(x)p(x))2]−(Ex∼q[f(x)q(x)p(x)])2=Ex∼p[f(x)2[q(x)p(x)]−(Ex∼p[f(x)])2
方差主要差别在第一项,也就是q(x)p(x)的值。所以如果p和q差很多,而且采样不够多,区别就差很大。当然,如果sample次数足够多,那么期望相同,也没有太大区别。
Off-policy
∇Rˉθ=Eτ∼pθ′(τ)[pθ′(τ)pθ(τ)R(τ)∇logpθ(τ)]
θ′ sample一次data,可以给 θ uptake很多次,完了以后再去 Sample data
Add Constraint
Actor-Critic
减小Actor的方差:Causality方法
策略梯度的公式变为
∇J(θ)=N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)(t′=t∑Tr(si,t′,ai,t′))
即后一项关于的奖励的累加只累加当前时间步t之后的奖励,直观的理解是t′时刻策略的改变不会影响到t′之前时间步的奖励
在上式中,对∑t=1T∇θlogπθ(ai,t∣si,t)使用的是Monte Carlo估计方法,这种方法方差大。将该项可以写成Q^i(st,at),Q值代表未来的累计奖励的期望,可以使用值函数近似的方法来估计Q^i(st,at) ,从而进一步减少方差。
∇J(θ)=N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)Q^i(st,at)
Baseline方法
如果希望在上式的基础上,进一步减少方差,那么可以为Q^i(st,at) 添加baseline ,将baseline记为b,则策略梯度的公式为
∇J(θ)=N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)(Q^(st,at)−b)
可以证明,只有在b与动作at无关的情况下,上述改进才与之前的策略梯度公式等价。b一般选择为状态st的值函数(还与θ有关?),即b=v^i(s) 。
当baseline是状态值函数时,策略梯度可以写成
∇J(θ)=N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)(Q^(st,at)−V^(st))
其中, Q^(st,at)−V^(st)=A^(st,at)称为Advantage Function,其中
Q(st,at)=r(st,at)+st+1∑P(st+1∣st,at)[V(st+1)]
如果不考虑状态转移概率,用采样的方式来估计状态转移,则在当前策略参数下,
Q(st,at)≈r(st,at)+V(st+1)
因此策略梯度公式可以进一步写成
∇J(θ)=N1i=1∑Nt=1∑T∇θlogπθ(ai,t∣si,t)(r(st,at)+V^(st+1)−V^(st))
在上式中,我们需要估计状态值函数V^(st)的值。用于估计V^(st)的部分被称为Critic。
Actor-Critic的基本流程为:
采样→更新Critic参数→根据Critic计算AdvantageFunction→更新Actor参数
参考
https://blog.51cto.com/u_15721703/5575736
https://www.zhihu.com/question/56692640/answer/289913574
[https://danieltakeshi.github.io/2017/03/28/going-deeper-into-reinforcement-learning-fundamentals-of-policy-gradients/](