了解Llama
了解Llama
文章:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
介绍
This release includes model weights and starting code for pretrained and fine-tuned Llama language models — ranging from 7B to 70B parameters(7B, 13B, 70B).
Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.
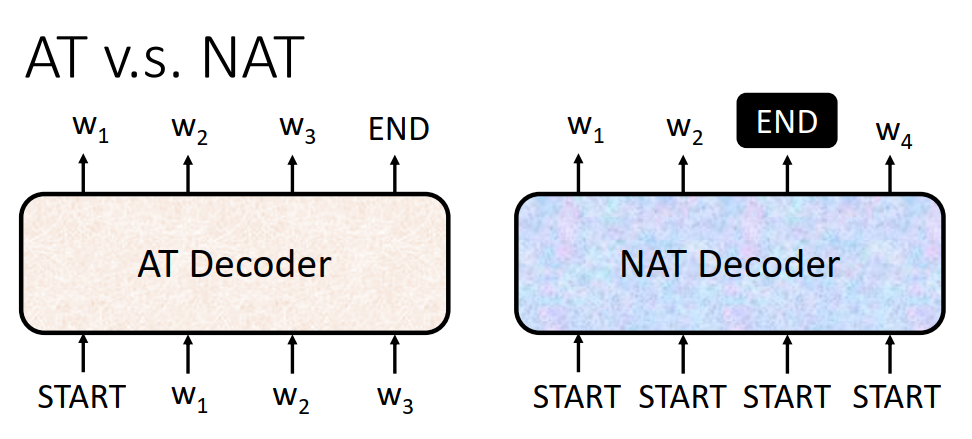
Auto-regressive transformers are pretrained on an extensive corpus of self-supervised data, followed by alignment with human preferences via techniques such as Reinforcement Learning with Human Feedback (RLHF).
Auto-regression is a time series model that uses observations from previous time steps as input to a regression equation to predict the value at the next time step
Llama2模型训练包括:预训练,有监督微调,RLHF。
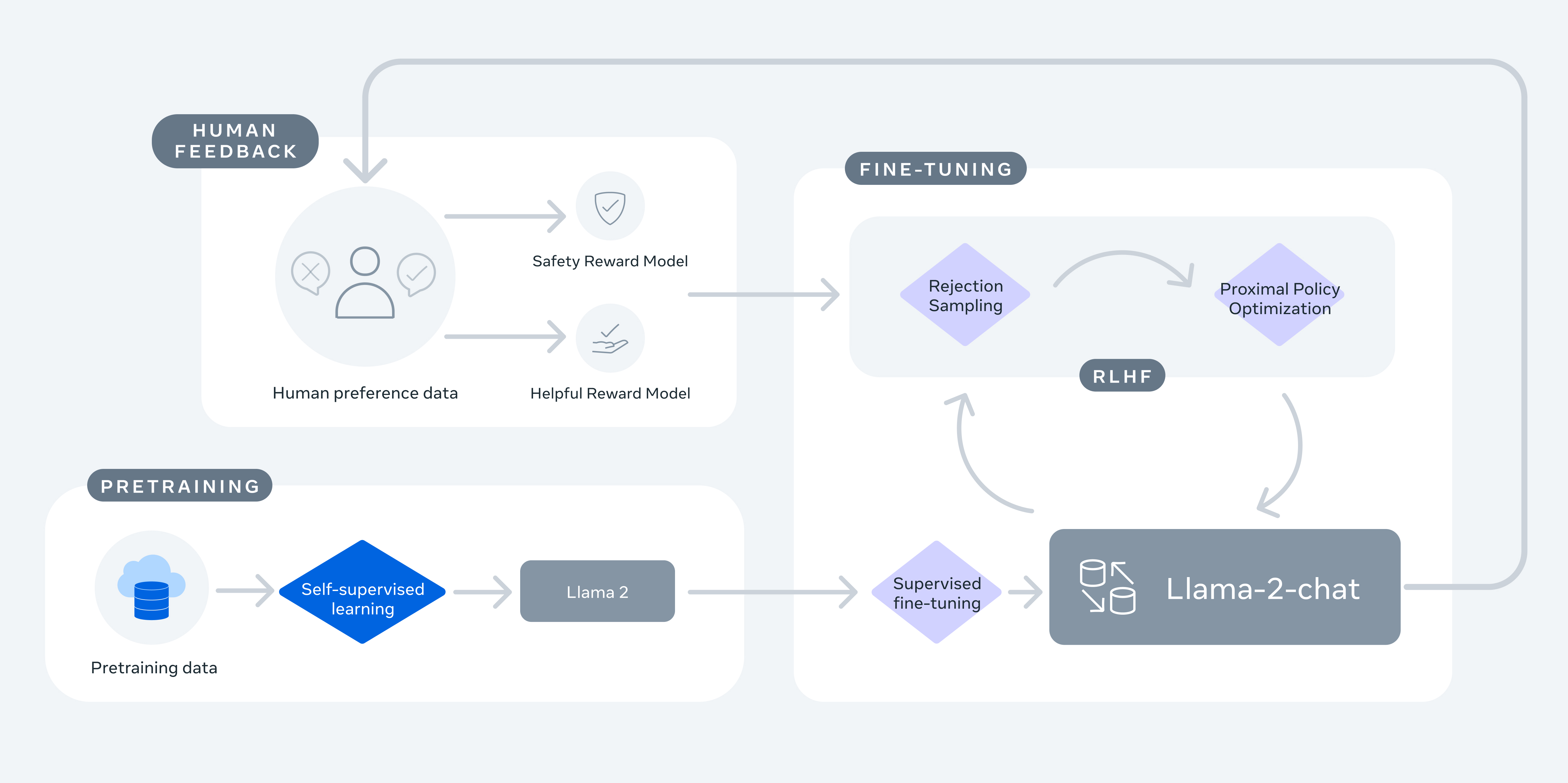
The training methodology is simple, but high computational requirements.
训练
预训练数据
-
训练语料库包括来自公开来源的新数据组合,其中不包括来自 Meta 产品或服务的数据。
-
剔除某些已知包含大量个人隐私信息的网站的数据。
-
在 2 万亿个tokem的数据上进行了训练,很好地权衡性能与成本。
-
对最真实的数据源进行上采样,以增加知识和减少错误。
训练细节
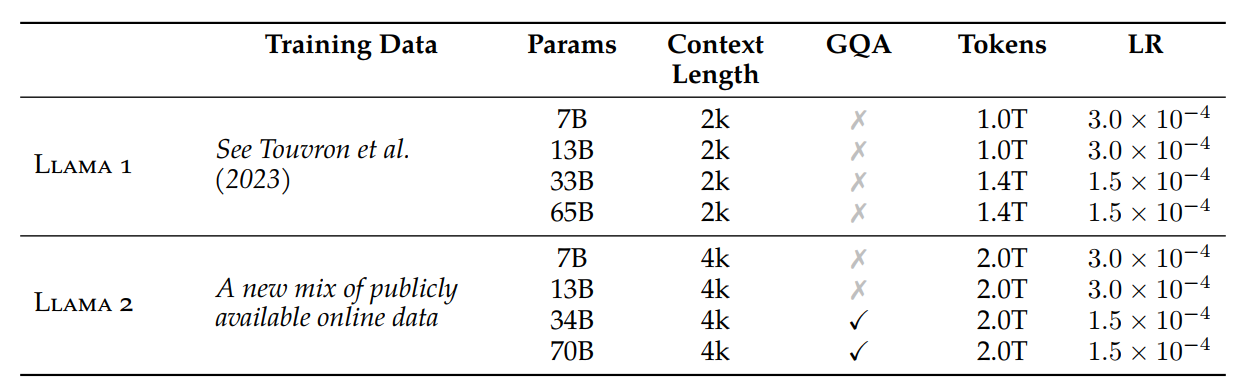
We adopt most of the pretraining setting and model architecture from Llama 1. We use the standard transformer architecture (Vaswani et al., 2017), apply pre-normalization using RMSNorm (Zhang and Sennrich, 2019), use the SwiGLU activation function (Shazeer, 2020), and rotary positional embeddings (RoPE, Su et al. 2022). The primary architectural differences from Llama 1 include increased context length and grouped-query attention (GQA).
LayerNorm是对特征张量按照某一维度或某几个维度进行0均值,1方差的归一化。RMSNorm是对LayerNorm的一个改进,没有做re-center操作(移除了其中的均值项)。RMSNorm 也是一种标准化方法,但与 LayerNorm 不同,它不是使用整个样本的均值和方差,而是使用平方根的均值来归一化,这样做可以降低噪声的影响。
旋转式位置编码(RoPE)最早是一种能够将相对位置信息依赖集成到self-attention中并提升transformer架构性能的位置编码方式。
GQA(Grouped-Query Attention)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。其中多个查询头关注相同的键和值头,以减少推理过程中 KV 缓存的大小,并可以显著提高推理吞吐量。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
-
Hyperparameters
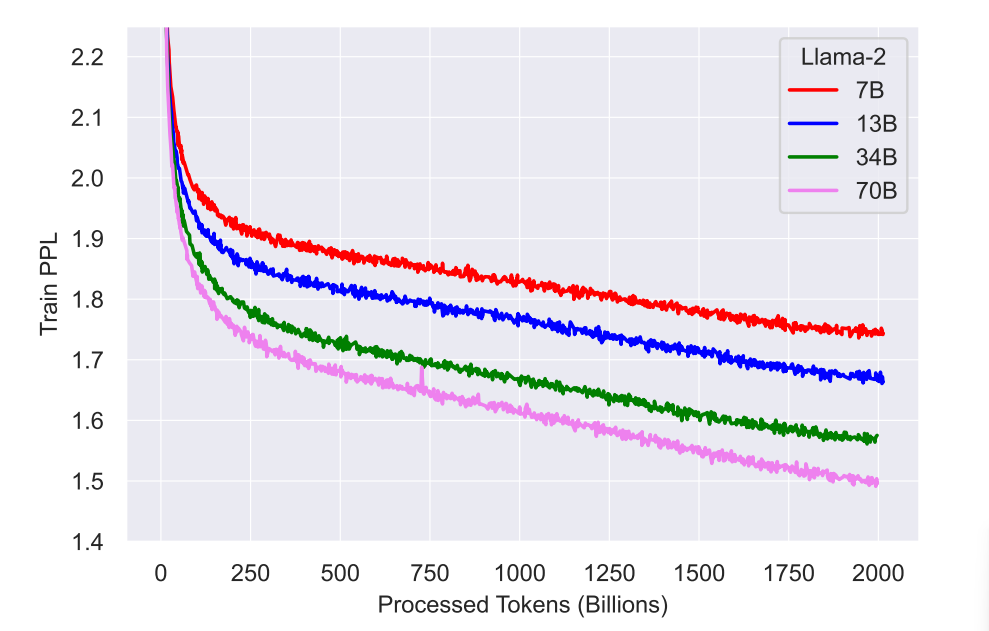
We trained using the AdamW optimizer (Loshchilov and Hutter, 2017), with β1 = 0.9, β2 = 0.95, eps = 10-5. We use a cosine learning rate schedule, with warmup of 2000 steps, and decay final learning rate down to 10% of the peak learning rate. We use a weight decay of 0.1 and gradient clipping of 1.0.
-
Tokenizer
We use the same tokenizer as Llama 1; it employs a bytepair encoding (BPE) algorithm (Sennrich et al., 2016) using the implementation from SentencePiece (Kudo and Richardson, 2018). As with Llama 1, we split all numbers into individual digits and use bytes to decompose unknown UTF-8 characters. The total vocabulary size is 32k tokens.
-
Llama 2预训练模型评估
- 和开源模型对比,Llama 2性能最好。
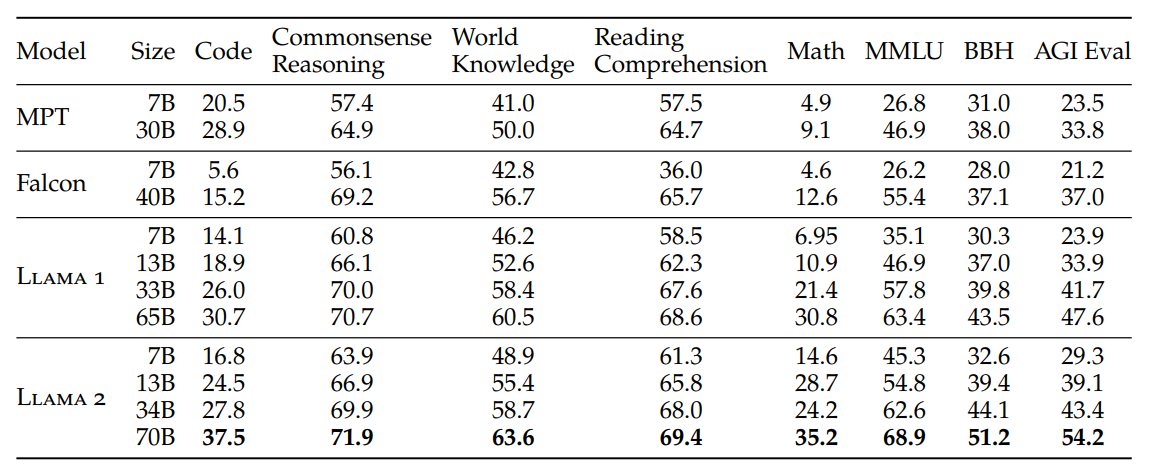
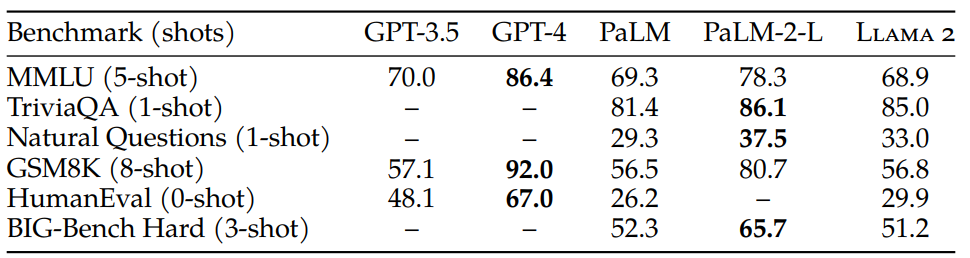
- 和闭源模型对比,Llama 2有很大的性能差距。
微调
Llama 2-Chat 是数月研究和反复应用对齐(alignment)技术的成果,包括指令调整(instruction tuning)和 RLHF,需要大量的计算和注释资源。
Supervised Fine-Tuning (SFT)
-
Getting Started
To bootstrap, we started the SFT stage with publicly available instruction tuning data (Chung et al., 2022), as utilized previously in Touvron et al. (2023).
-
Quality Is All You Need
By setting aside millions of examples from third-party datasets and using fewer but higher-quality examples from our own vendor-based annotation efforts, our results notably improved.
For the fine-tuning process, each sample consists of a prompt and an answer. To ensure the model sequence length is properly filled, we concatenate all the prompts and answers from the training set. A special token is utilized to separate the prompt and answer segments. We utilize an autoregressive objective and zero-out the loss on tokens from the user prompt, so as a result, we backpropagate only on answer tokens. Finally, we fine-tune the model for 2 epochs.
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a model training procedure that is applied to a fine-tuned language model to further align model behavior with human preferences and instruction following. We collect data that represents empirically sampled human preferences, whereby human annotators select which of two model outputs they prefer. This human feedback is subsequently used to train a reward model, which learns patterns in the preferences of the human annotators and can then automate preference decisions.
-
Human Preference Data Collection
Our annotation procedure proceeds as follows. We ask annotators to first write a prompt, then choose between two sampled model responses, based on provided criteria. In order to maximize the diversity, the two responses to a given prompt are sampled from two different model variants, and varying the temperature hyper-parameter. In addition to giving participants a forced choice, we also ask annotators to label the degree to which they prefer their chosen response over the alternative: either their choice is significantly better, better, slightly better, or negligibly better/ unsure.
For our collection of preference annotations, we focus on helpfulness and safety.
Llama 2-Chat improvement also shifted the model’s data distribution. Since reward model accuracy can quickly degrade if not exposed to this new sample distribution, i.e., from hyper-specialization (Scialom et al., 2020b), it is important before a new Llama 2-Chat tuning iteration to gather new preference data using the latest Llama 2-Chat iterations. This step helps keep the reward model on-distribution and maintain an accurate reward for the latest model.
-
Reward Modeling
The reward model takes a model response and its corresponding prompt (including contexts from previous turns) as inputs and outputs a scalar score to indicate the quality (e.g., helpfulness and safety) of the model generation.
Helpfulness and safety sometimes trade off (Bai et al., 2022a), which can make it challenging for a single reward model to perform well on both. To address this, we train two separate reward models, one optimized for helpfulness (referred to as Helpfulness RM) and another for safety (Safety RM).
Training Objectives
where is the scalar score output for prompt and completion with model weights . is the preferred response that annotators choose and is the rejected counterpart. Margin is a discrete function of the preference rating. Naturally, we use a large margin for pairs with distinct responses, and a smaller one for those with similar responses.
-
Iterative Fine-Tuning
Two main algorithms
-
Proximal Policy Optimization (PPO) (Schulman et al., 2017), the standard in RLHF literature.
近端策略优化(proximal policy optimization,PPO),通过重要性采样把同策略换成异策略。
https://datawhalechina.github.io/easy-rl/#/chapter5/chapter5
-
Rejection Sampling fine-tuning. We sample K outputs from the model and select the best candidate with our reward. Here, we go one step further, and use the selected outputs for a gradient update. For each prompt, the sample obtaining the highest reward score is considered the new gold standard. Similar to Scialom et al. (2020a), we then fine-tune our model on the new set of ranked samples, reinforcing the reward.
挑出分数最高的response作为training target,做supervised fine-tuning (SFT)。
We perform rejection sampling only with our largest 70B Llama 2-Chat. All smaller models are fine-tuned on rejection sampled data from the larger model, thus distilling the large-model capabilities into the smaller ones.
-
使用Llama
https://huggingface.co/docs/transformers/main/en/model_doc/llama
https://huggingface.co/docs/transformers/main/en/model_doc/llama2
- 下载模型参数。Weights for the LLaMA models can be obtained from by filling out this form
- 转换为Hugging Face格式。After downloading the weights, they will need to be converted to the Hugging Face Transformers format using the conversion script. The script can be called with the following (example) command:
1 | |
- 加载模型和tokenizer。After conversion, the model and tokenizer can be loaded via:
1 | |