LLM自动评价方法
大语言模型自动评价方法
LLM的自动评估是一种常见的,可能也是最受欢迎的评估方法,通常使用标准度量或指标以及评估工具来评估模型的性能,如准确性、BLEU(Papineni et al.,2002)、ROUGE(Lin,2004)、BERTScore(Zhang et al.,2019)等。由于其主观性、自动计算性和简单性,大多数现有的评估工作都采用了这种评估协议。因此,大多数确定性任务,如自然语言理解和数学问题,通常采用这种评估协议。
与人工评估相比,自动评估不需要密集的人工参与,节省了成本和时间。最近,随着LLM的发展,一些先进的自动评估技术也被设计来帮助评估。林和陈(2023)提出了LLM-EVAL,这是一种使用LLM进行开放域对话的统一多维度自动评估方法。PandaLM(Wang et al.,2023h)可以通过训练LLM来评估不同的模型,从而实现可复现和自动化的语言模型评估。Jain(2023)等人提出了一个自监督的评估框架,通过消除对新数据的费力标注,实现了在现实世界部署环境中评估模型的更有效形式。
Automatic Evaluation
1. Acuracy
2. BLEU
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
神经网络生成的句子是candidate,给定的标准译文是reference。
-
lc=candidate的长度,lr=最短的reference的长度
-
BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。避免当机器翻译的长度比较短时,BLEU 得分也会比较高,但是这个翻译是会损失很多信息的。
-
BLEU 需要计算译文 1-gram,2-gram,…,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。n-gram是连续n个词的组合。
-
BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
-
Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
Count(n-gram’)表示n−gram′在candidate中的个数,
3. ROUGE
Lin, C.-Y. (2004). Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- ROUGE-N: 在 N-gram 上计算召回率
- ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列
- ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列
ROUGE-N 主要统计 N-gram 上的召回率,对于 N-gram,可以计算得到 ROUGE-N 分数,计算公式如下:
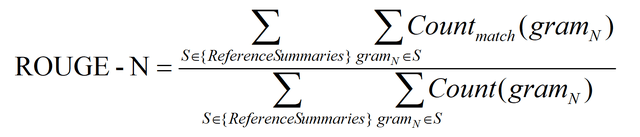
公式的分母是统计在reference中N-gram 的个数,而分子是统计reference与candidate共有的 N-gram 个数。
给定多个参考译文 Si
ROUGE-L 中的 L 指最长公共子序列 (longest common subsequence, LCS),ROUGE-L 计算的时候使用了机器译文C和参考译文S的最长公共子序列,计算公式如下:
公式中的 RLCS 表示召回率,而 PLCS 表示精确率,FLCS 就是 ROUGE-L。一般 beta 会设置为很大的数,因此 FLCS 几乎只考虑了 RLCS (即召回率)。**注意这里 beta 大,则 F 会更加关注 R,而不是 P,可以看下面的公式。**如果 beta 很大,则 PLCS 那一项可以忽略不计。
ROUGE-W 是 ROUGE-L 的改进版,使用一种加权最长公共子序列方法 (WLCS),给连续翻译正确的更高的分数。
ROUGE-S 也是对 N-gram 进行统计,但是其采用的 N-gram 允许"跳词 (Skip)",即单词不需要连续出现。
4. self-supervised evaluation framework
Jain, N., Saifullah, K., Wen, Y., Kirchenbauer, J., Shu, M., Saha, A., Goldblum, M., Geiping, J., and Goldstein, T. (2023). Bring your own data! self-supervised evaluation for large language models. arXiv preprint arXiv:2306.13651.
目前的评估使用带有人工策划标签的小型领域特定数据集,这些评估集通常从狭窄而简化的分布中抽样,数据源可能会在不知不觉中泄露到培训集,这可能会导致误导性评估。
We demonstrate self-supervised evaluation strategies for measuring closed-book knowledge, toxicity, and long-range context dependence, in addition to sensitivity to grammatical structure and tokenization errors.
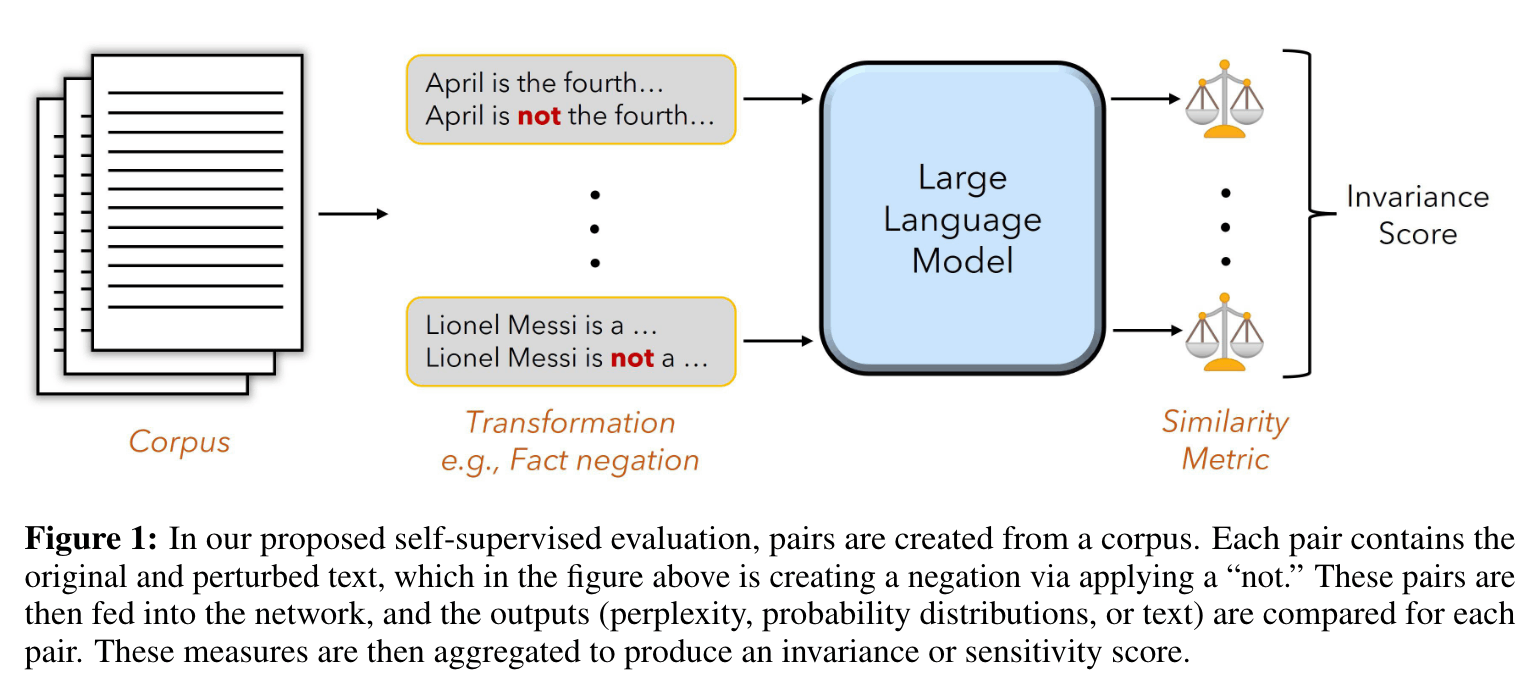
Based on this intervention, we measure the change in the log-perplexity (log(ppl(x))), between the original and negated sentence. Formally, we define the sensitivity score as the following:
接下来是第二类方法,称为“间接或分解的启发式方法(indirect or decomposed heuristics)”。在这种方法中,我们利用较小的模型(smaller models)来评估主模型(the main model)生成的答案,这些较小的模型可以是微调过的模型或原始的分解模型(raw decompositions)。其核心思想是选取在这些大模型擅长的任务上表现更好的小模型来进行评估。这些较小模型的输出被看作是弱得分(weak scores),然后将它们结合起来为生成的输出提供一个最终的标签或评价。这种间接评估方法能够更加细致地评估模型的性能,尤其在判断对散文的喜爱程度等这些任务。
5. BERTScore
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y. (2019). Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675.
基于N-gram重叠的度量标准只对词汇变化敏感,不能识别句子语义或语法的变化。因此,它们被反复证明与人工评估差距较大。
于是有人提出使用句子上下文表示(bert全家桶)和人工设计的计算逻辑对句子相似度进行计算。这样的评价指标鲁棒性较好,在缺乏训练数据的情况下也具有较好表现。
思路是非常简单的:即对两个生成句和参考句(word piece进行tokenize)分别用bert提取特征,然后对2个句子的每一个词分别计算内积,可以得到一个相似性矩阵。
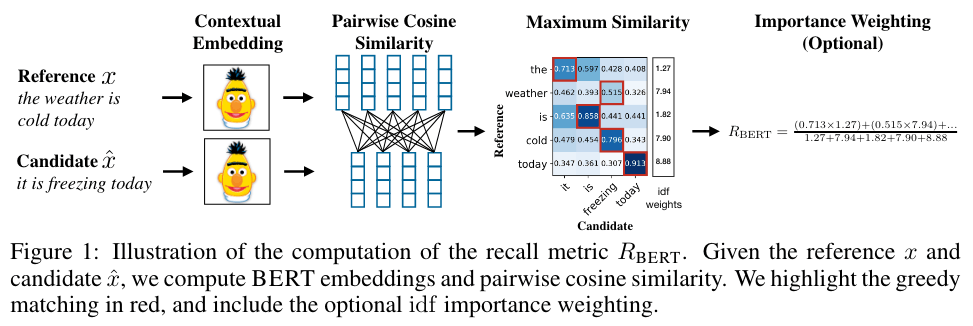
基于这个矩阵,我们可以分别对参考句和生成句做一个最大相似性得分的累加然后归一化,得到bertscore的precision,recall和F1:
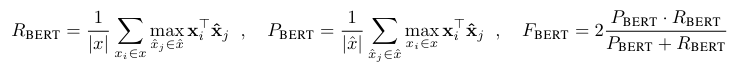
还可以考虑给不同的词以权重。作者使用idf函数,即给定M个参考句,词w的idf为:
其中是一个指示函数。用此式更新上述评分,例如recall:
6. LLM-EVAL
Lin, Y.-T. and Chen, Y.-N. (2023). Llm-eval: Unified multidimensional automatic evaluation for open-domain conversations with large language models. arXiv preprint arXiv:2305.13711.
The single prompt is created by concatenating the dialogue context, reference (if available), and generated response, and then fed to a large language model, which outputs scores for each dimension based on the defined schema.xs

-
Unified Evaluation Schema
The evaluation schema is a natural language instruction that defines the task and the desired evaluation criteria. The schema is provided as a format instruction, which specifies the structure and the range of the scores for each dimension. For example, the evaluation schema can be:

-
Single Prompt for Evaluation
The prompt is concatenated with the dialogue context, the reference (if available), and the generated response, and then fed to the large language model to output a score for each evaluation dimension, based on the defined schema.

-
Efficient Evaluation
By using a single prompt with a unified evaluation schema, LLM-EVAL can efficiently obtain multi-dimensional scores for the responses without the need for multiple prompts.

-
Different LLMs
In conclusion, our analysis demonstrates that dialogue-optimized LLMs, such as Claude and ChatGPT, yield better performance in the LLMEVAL method for open-domain conversation evaluation. Although smaller models like Anthropic Claude-instant may not achieve the best performance, they can still be considered for resourcelimited scenarios.
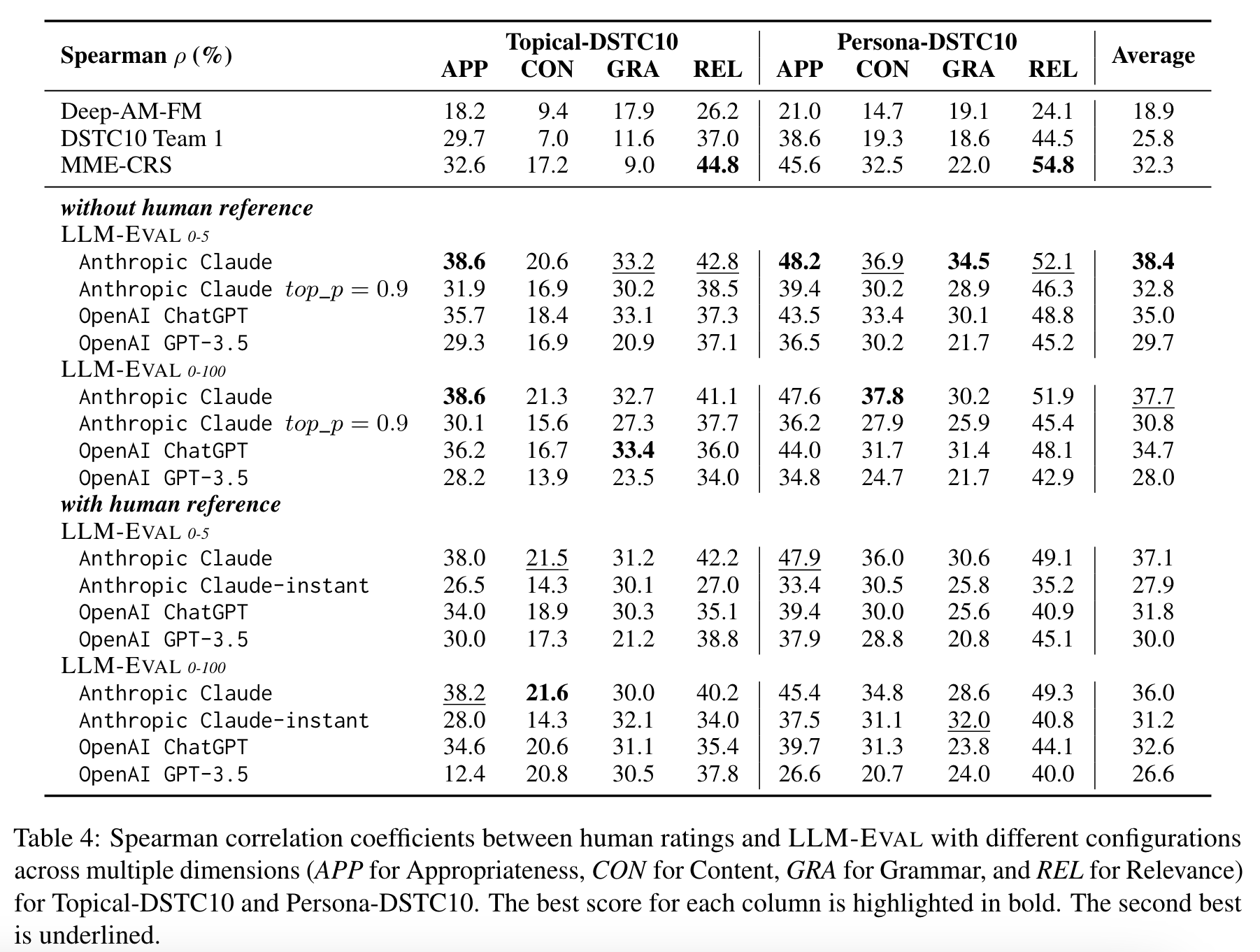
-
Baseline Evaluation Metrics
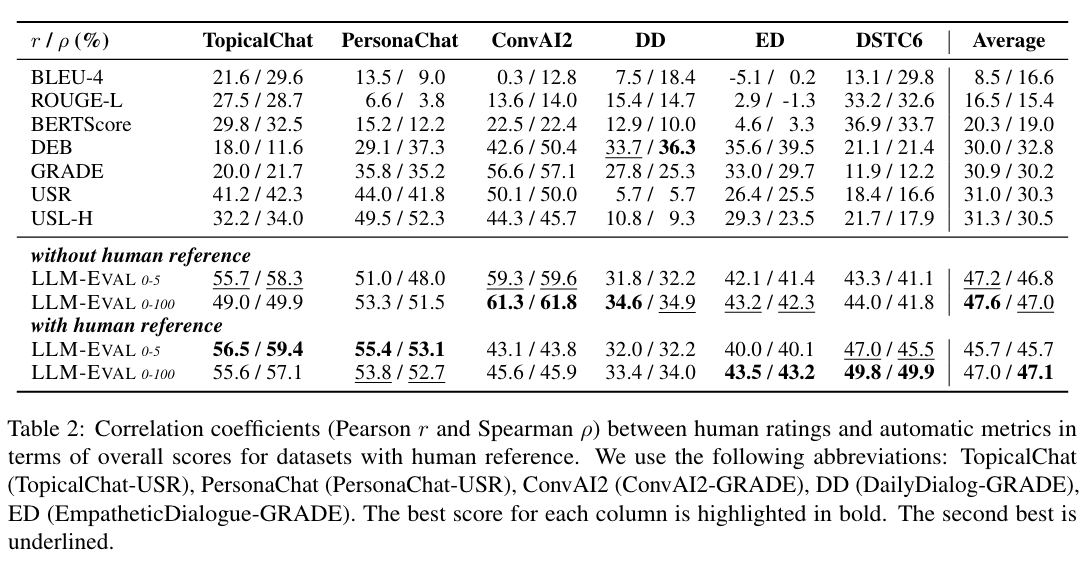
7. PandaLM
Wang, Y., Yu, Z., Zeng, Z., Yang, L., Wang, C., Chen, H., Jiang, C., Xie, R., Wang, J., Xie, X., et al. (2023h). Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization. arXiv preprint arXiv:2306.05087.
当前,大家评估大模型的方法主要有两个:
- 调用OpenAI的API接口,发送数据给OpenAI可能会像三星员工泄露代码一样造成数据泄露问题。
- 雇佣专家进行人工标注,雇佣专家标注大量数据又十分费时费力且昂贵。
PandaLM只需要在「本地部署」,且「不需要人类参与」,因此PandaLM的评估是可以保护隐私且相当廉价的。
当两个不同的大模型对同一个指令和上下文产生不同响应时,PandaLM旨在比较这两个大模型的响应质量,并输出比较结果,比较理由以及可供参考的响应。比较结果有三种:响应1更好,响应2更好,响应1与响应2质量相似。
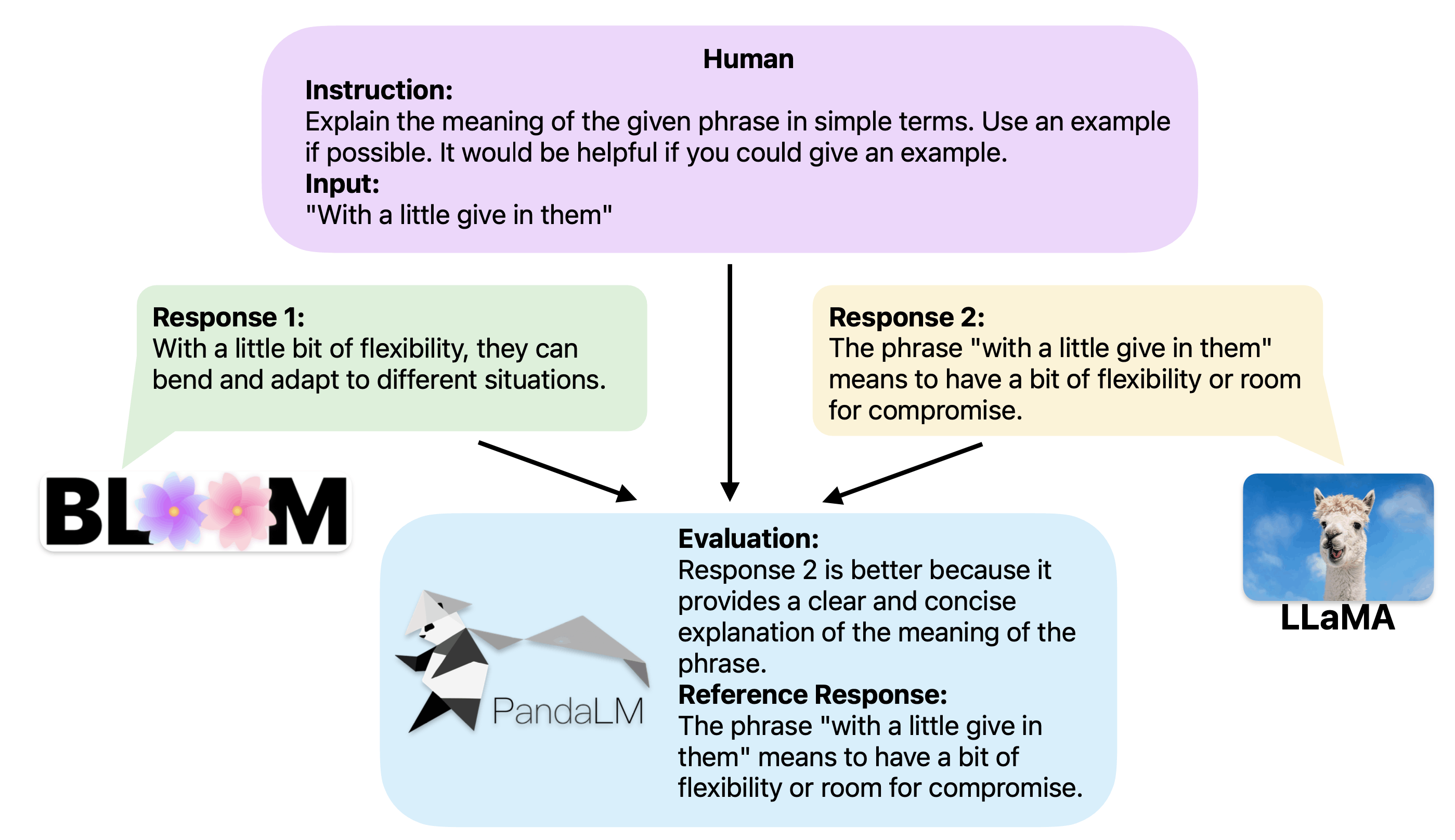
结果表明,PandaLM-7B达到了93.75%的GPT-3.5评价能力和88.28%的GPT-4评价能力。
