概率评分方法
概率评分方法
一般来说,评估预测概率准确性的方法被称为评分规则或评分函数。下面将介绍三种评分方法,可用于评估分类预测建模问题的预测概率。
Log Loss Score
Log loss, also called “logistic loss,” “logarithmic loss,” or “cross entropy” can be used as a measure for evaluating predicted probabilities.
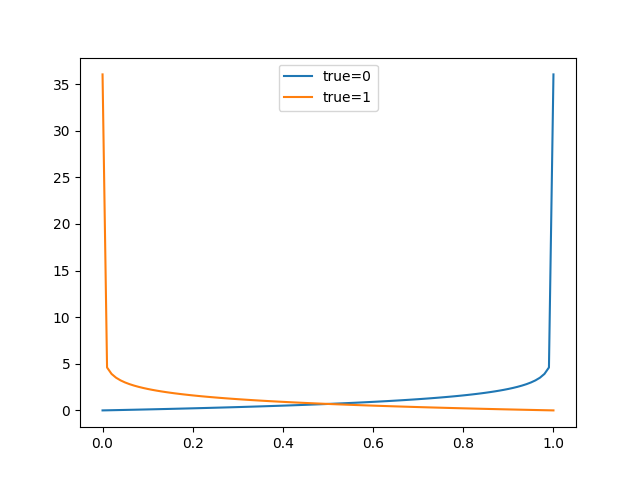
将每个预测概率与实际类输出值(0或1)进行比较,并计算出一个分数,该分数根据与预期值的距离来惩罚概率。惩罚是对数的,小差异的分数小和大差异的分数大。
对于带有真实标签的单个样品 和概率估计 , log loss 是:
缺点
Log loss的结果对数据集取平均,在平衡数据集的情况下,分数将是合适的,在不平衡数据集的情况下,分数将具有误导性。
平衡数据集Log Loss预测的折线图
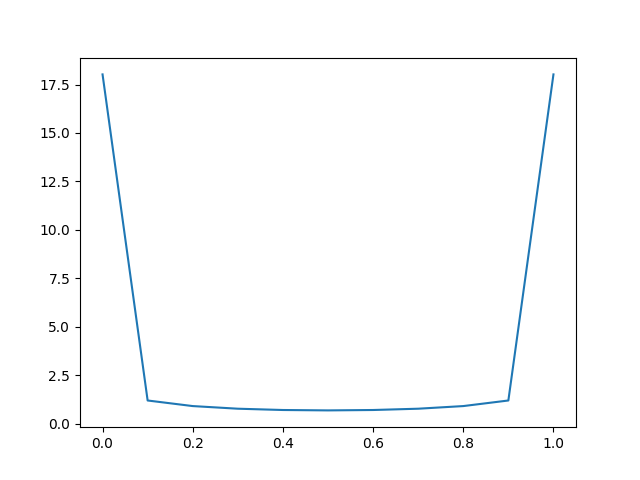
不平衡数据集(0多)Log Loss预测的折线图
实现
1 | |
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.log_loss.html
Brier Score
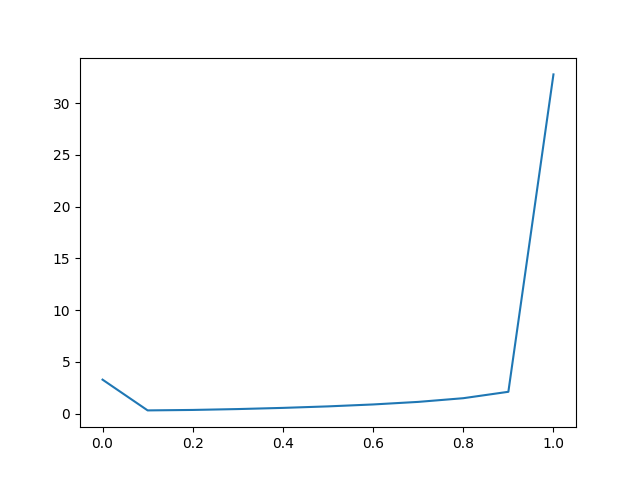
Brier Score衡量的是预测概率和实际结果之间的均方差。分数汇总了概率预测中误差的大小。错误分数始终在0.0和1.0之间,其中完美的模型的分数为0。
实现
1 | |
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.brier_score_loss.html
与Log loss一样,在不平衡数据集的情况下,分数将具有误导性。
ROC AUC Score
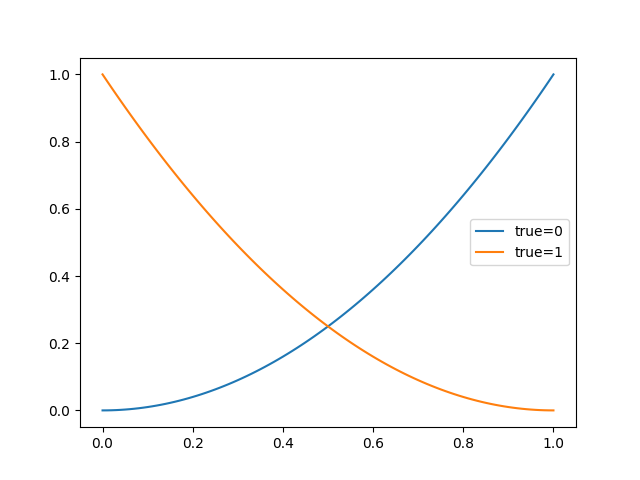
ROC(Receiver Operating Characteristic)曲线是一种用于表示分类模型性能的图形工具。它通过将真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)作为横纵坐标来描绘分类器在不同阈值下的性能。
真阳性率(True Positive Rate,TPR)是指分类器正确识别正例的能力,可以理解为所有阳性群体中被检测出来的比率,TPR越接近1越好。
假阳性率(False Positive Rate,FPR)是指在所有实际为负例的样本中,模型错误地预测为正例的样本比例,FPR越接近0越好。

sklearn LogisticRegression 的ROC曲线:
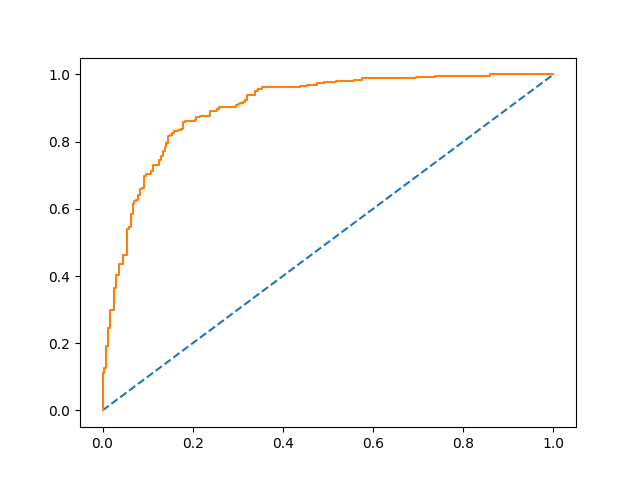
AUC(Area Under roc Curve)是ROC曲线下的面积,用于衡量分类器性能。AUC值越接近1,表示分类器性能越好;反之,AUC值越接近0,表示分类器性能越差。在实际应用中,我们常常通过计算AUC值来评估分类器的性能。
ROC曲线围成的面积 (即AUC)可以解读为:从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。
AUC的一般判断标准:
0.5 - 0.7:效果较低,但用于预测股票已经很不错了
0.7 - 0.85:效果一般
0.85 - 0.95:效果很好
0.95 - 1:效果非常好,但一般不太可能
优点
TPR用到的TP和FN同属P列,FPR用到的FP和TN同属N列,所以即使P或N的整体数量发生了改变,也不会影响到另一列。也就是说,即使正例与负例的比例发生了很大变化,ROC曲线也不会产生大的变化,而像Precision使用的TP和FP就分属两列,则易受类别分布改变的影响。
缺点
在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,ROC曲线的横轴采用FPR,根据,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。
实现
-
roc_curve函数1
2fpr, tpr, thresholds = sklearn.metrics.roc_curve(y_true, y_score)
pyplot.plot(fpr, tpr)https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
-
roc_auc_score函数1
auc_score = sklearn.metrics.roc_auc_score(y_true, y_score)https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html